Introducción
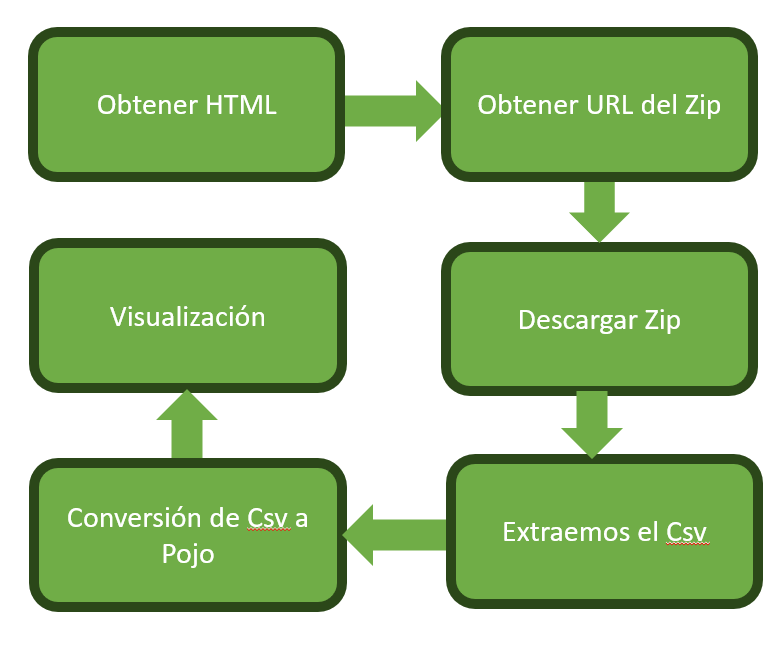
En este post, te mostraré cómo obtener información de empresas peruanas utilizando su RUC mediante web scraping con Java y la librería Jsoup. Para ello, realizaremos una solicitud a la web de SUNAT, extraeremos el enlace del archivo ZIP con los datos y procesaremos la información en formato CSV.
Sunat no ofrece un servicio de api , público o gratuito ,por ello es que usamos WebScraping
Requisitos
Antes de comenzar, asegúrate de tener lo siguiente:
- Java 8 o superior instalado.
- Maven o Gradle para gestionar dependencias.
- La librería Jsoup agregada a tu proyecto.
Si usas Maven, agrégala en tu pom.xml:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>Paso 1: Hacer la solicitud a SUNAT
Para obtener la información de un RUC, primero necesitamos hacer una solicitud HTTP a la web de SUNAT. Utilizaremos HttpURLConnection para obtener el HTML de la página de consulta:
public static String ObtenerHTML(String ruc) {
String ENDPOINT = "https://e-consultaruc.sunat.gob.pe/cl-ti-itmrconsmulruc/jrmS00Alias?accion=consManual&selRuc=";
String url = ENDPOINT.concat(ruc);
StringBuilder response = new StringBuilder();
try {
URL obj = new URL(url);
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
con.setRequestMethod("GET");
con.setRequestProperty("User-Agent", "Mozilla/5.0");
con.setRequestProperty("Referer", "https://e-consultaruc.sunat.gob.pe/");
BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
} catch (Exception e) {
e.printStackTrace();
}
return response.toString();
}Paso 2: Extraer la URL del archivo ZIP
Después de obtener el HTML, necesitamos encontrar el enlace de descarga del ZIP que contiene los datos de la empresa. Para esto, utilizamos Jsoup:
public static String ObtenerURLZip(String htmlResponse) {
Document doc = Jsoup.parse(htmlResponse);
Elements links = doc.select("a");
for (Element link : links) {
String href = link.attr("href");
System.out.println("Href encontrado: " + href);
return href;
}
return "";
}Paso 3: Descargar y extraer el archivo ZIP
Con la URL del archivo ZIP en mano, procedemos a descargarlo y extraer su contenido:
public static byte[] descargarArchivo(String urlStr) throws IOException {
URL url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
if (connection.getResponseCode() == 200) {
try (InputStream inputStream = connection.getInputStream();
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
byteArrayOutputStream.write(buffer, 0, bytesRead);
}
return byteArrayOutputStream.toByteArray();
}
}
return null;
}Ahora, extraemos el contenido del archivo ZIP:
public static String extraerContenidoDeZip(byte[] zipBytes) throws IOException {
try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(zipBytes);
ZipInputStream zipInputStream = new ZipInputStream(byteArrayInputStream)) {
ZipEntry entry;
while ((entry = zipInputStream.getNextEntry()) != null) {
if (entry.getName().endsWith(".txt")) {
return leerArchivoDesdeZip(zipInputStream);
}
}
}
return null;
}
private static String leerArchivoDesdeZip(InputStream zipInputStream) throws IOException {
StringBuilder contenido = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(zipInputStream, StandardCharsets.UTF_8))) {
String linea;
while ((linea = reader.readLine()) != null) {
contenido.append(linea).append("\n");
}
}
return contenido.toString();
}Paso 4: Procesar el CSV y obtener los datos del RUC
El archivo extraído es un CSV delimitado por |, por lo que podemos dividir la información y obtener los datos relevantes:
private static String obtenerPrimerasLineas(String contenido, int numLineas) {
String[] lineas = contenido.split("\n");
StringBuilder resultado = new StringBuilder();
for (int i = 1; i < Math.min(numLineas, lineas.length); i++) {
resultado.append(lineas[i]).append("\n");
}
return resultado.toString();
}Finalmente, creamos un objeto Contribuyente con los datos obtenidos:
public class Contribuyente {
private String[] datos;
public Contribuyente(String[] datos) {
this.datos = datos;
}
@Override
public String toString() {
return "RUC: " + datos[0] + " - Razón Social: " + datos[1];
}
}Resultado Final
Cuando ejecutamos el código con un RUC válido, obtenemos información detallada sobre la empresa, como la razón social y estado actual:
OUTPUT:
----------------
RUC: 10718070932 - Razón Social: EMPRESA SACConsideraciones Finales
- Respeta los términos de uso de la web de SUNAT. Antes de hacer web scraping, revisa sus políticas.
- Usa cabeceras adecuadas. Para evitar bloqueos, es recomendable establecer un
User-Agentválido. - Optimiza el manejo de errores. Controla excepciones y valida respuestas antes de continuar con el procesamiento de datos.
Conclusión
Con este proyecto, logramos obtener información de empresas usando su RUC mediante web scraping en Java. Si te interesa aprender más sobre automatización con Java y Jsoup, déjamelo en los comentarios. ¡Nos vemos en el próximo post!
Además te dejo los links para que puedas utilizar la página y además descargar el código fuente del proyecto.
https://github.com/CesarsEren/webscraping-sunat-consulta-ruc
https://e-consultaruc.sunat.gob.pe/cl-ti-itmrconsmulruc/jrmS00Alias